Screenshots
Real UI from the current implementation: chat, document ingestion, provider settings, ingestion controls, retrieval controls and built-in help.
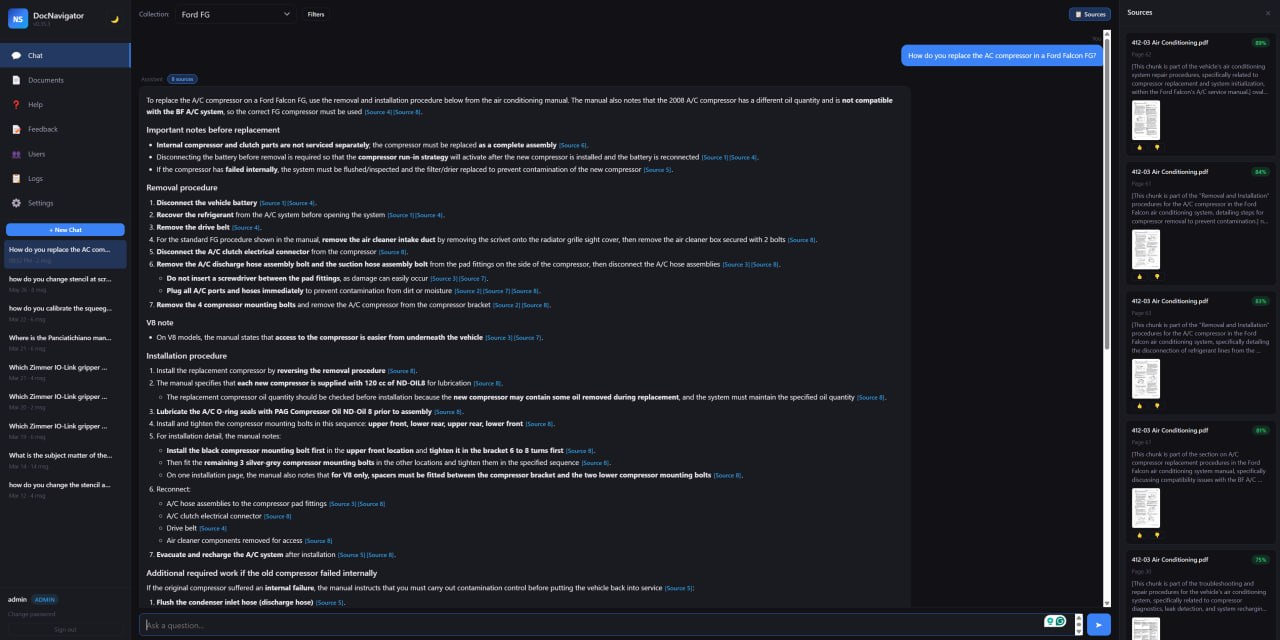
Chat
Ask natural-language questions and get cited answers with source documents, page references and follow-up prompts.
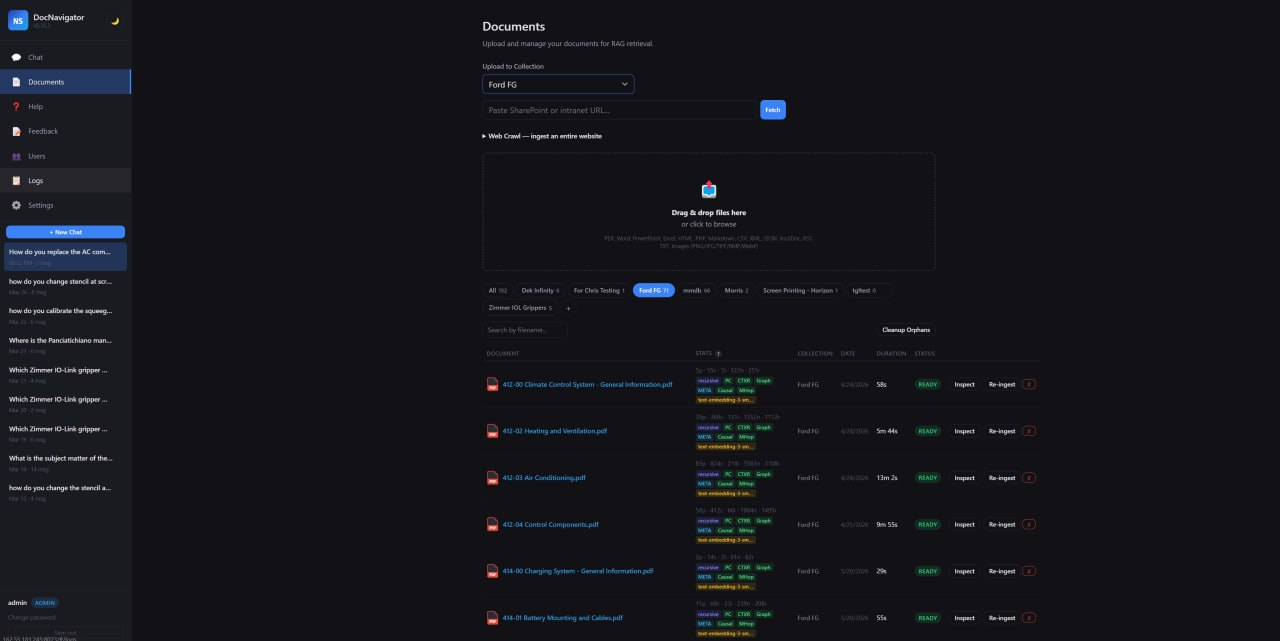
Documents
Upload files, fetch SharePoint/intranet URLs, crawl sites and manage processed documents by collection.
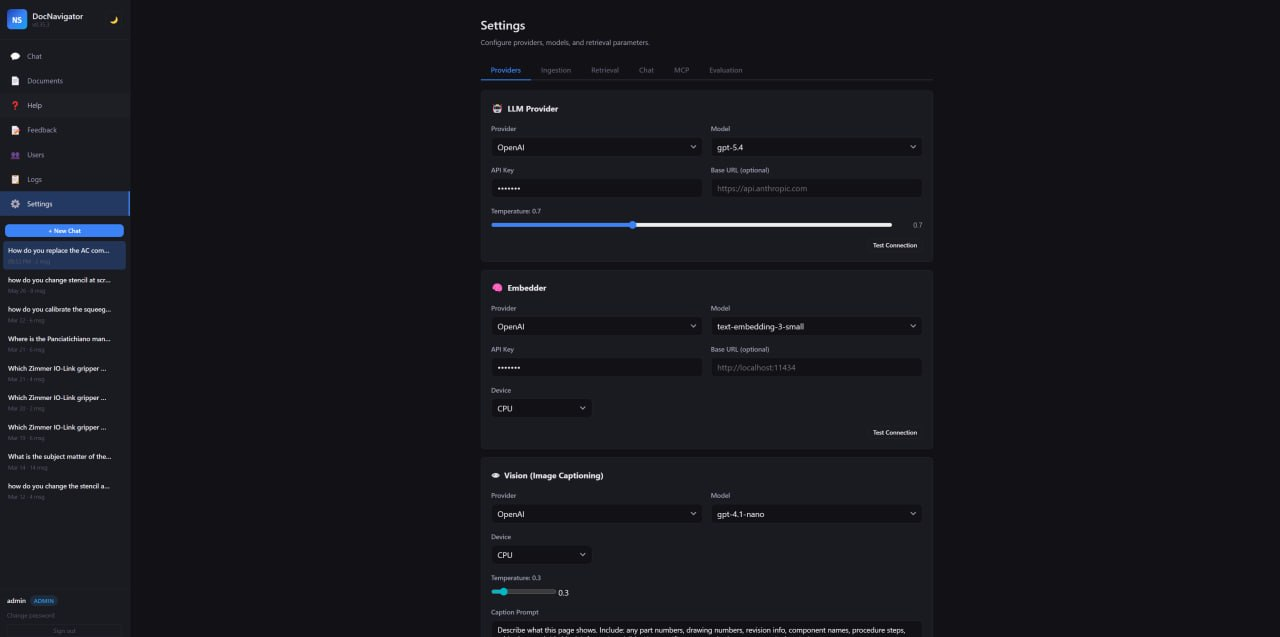
Provider Settings
Configure LLM, embedding and vision providers, test connections and keep API keys masked in the UI.
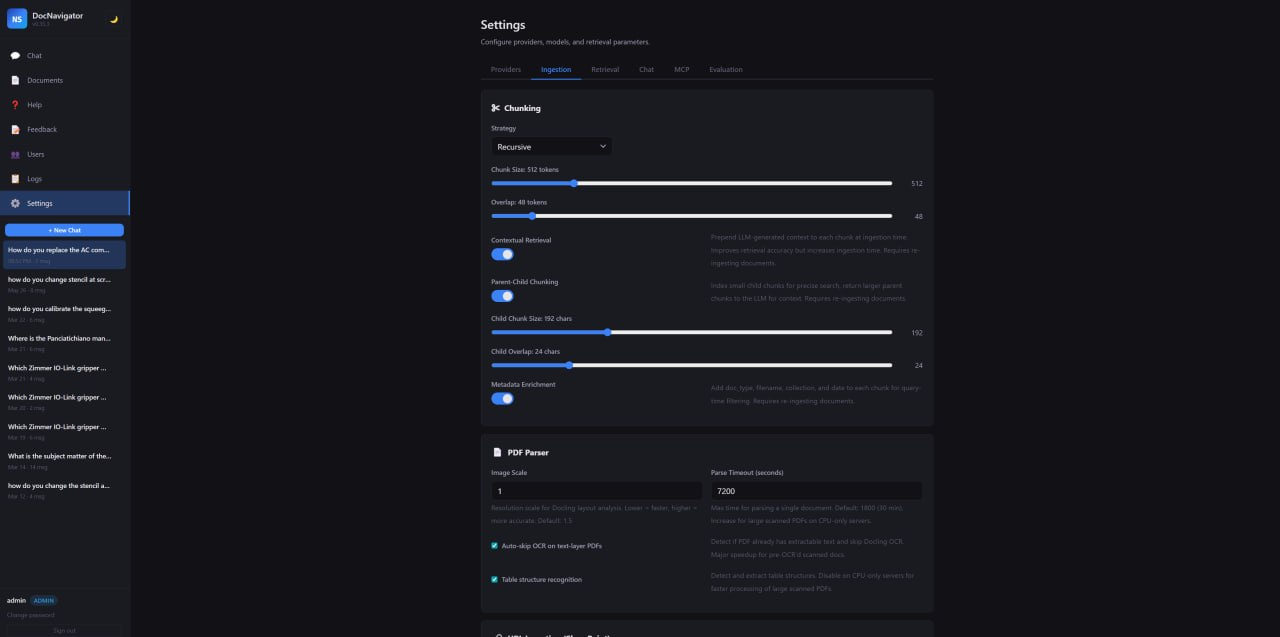
Ingestion Controls
Tune chunking, contextual retrieval, metadata enrichment, OCR, table recognition and parse timeouts.
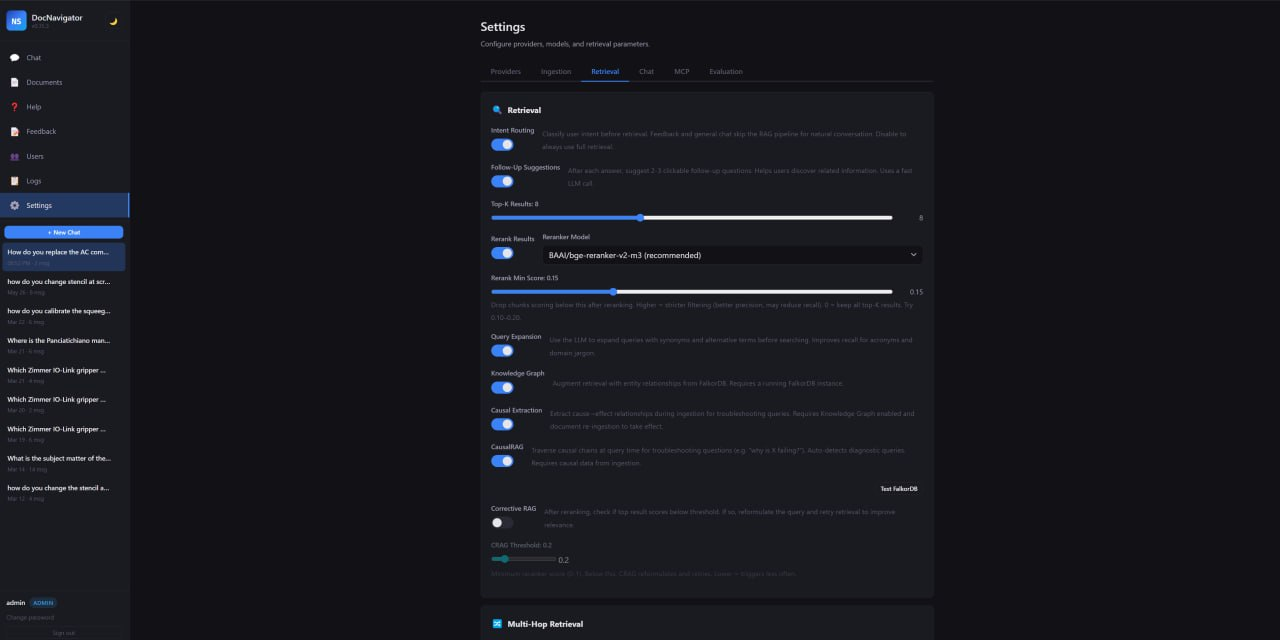
Retrieval Controls
Tune top‑k results, reranking, query expansion, knowledge graph retrieval, CausalRAG and corrective RAG.
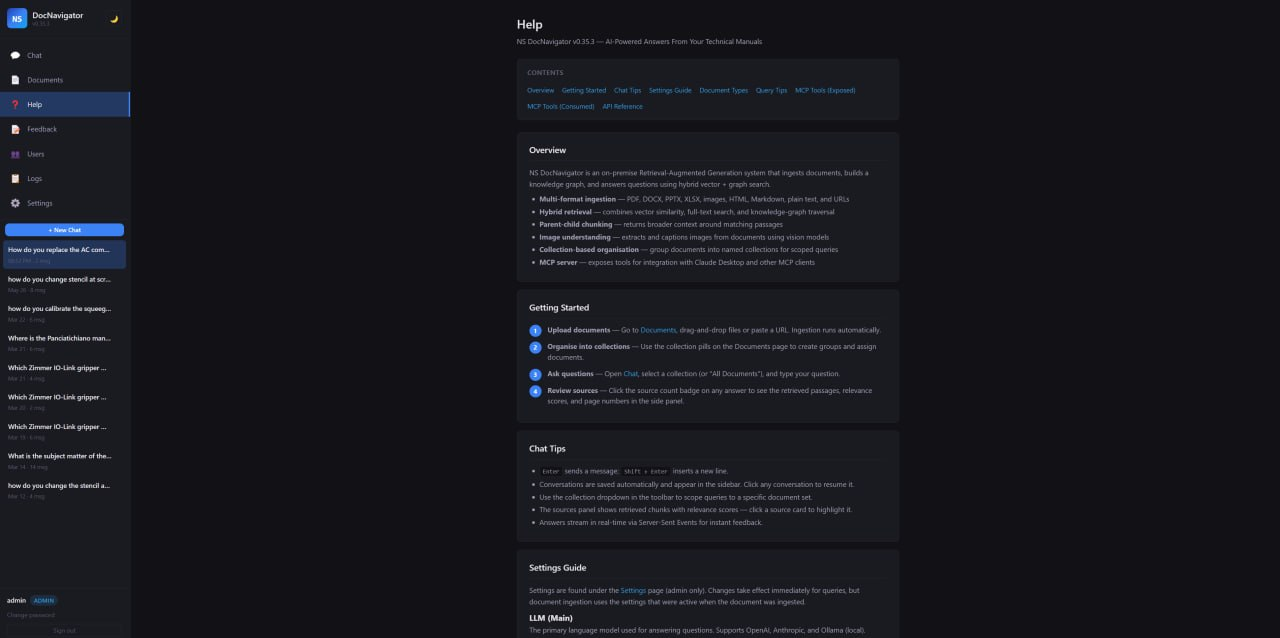
Built‑in Help
Inline documentation covers overview, getting started, chat tips, query tips, settings and MCP tooling.